













Apache Kafka is a versatile and powerful platform for handling real-time data streams, and it has become an essential component of many modern data architectures and applications. this platform has emerged as a cornerstone technology, enabling organizations to harness the power of real-time data in the fast-paced digital age. So we decided to examine Kafka and explain everything you need to know about it.
Apache Kafka is an open-source, distributed event streaming platform developed by the Apache Software Foundation. It is designed to handle real-time data streaming, making it a powerful tool for building data pipelines, event-driven architectures, and real-time data processing applications. In order to use this applicable platform it is recommended to buy Linux VPS services from the NeuronVM website.

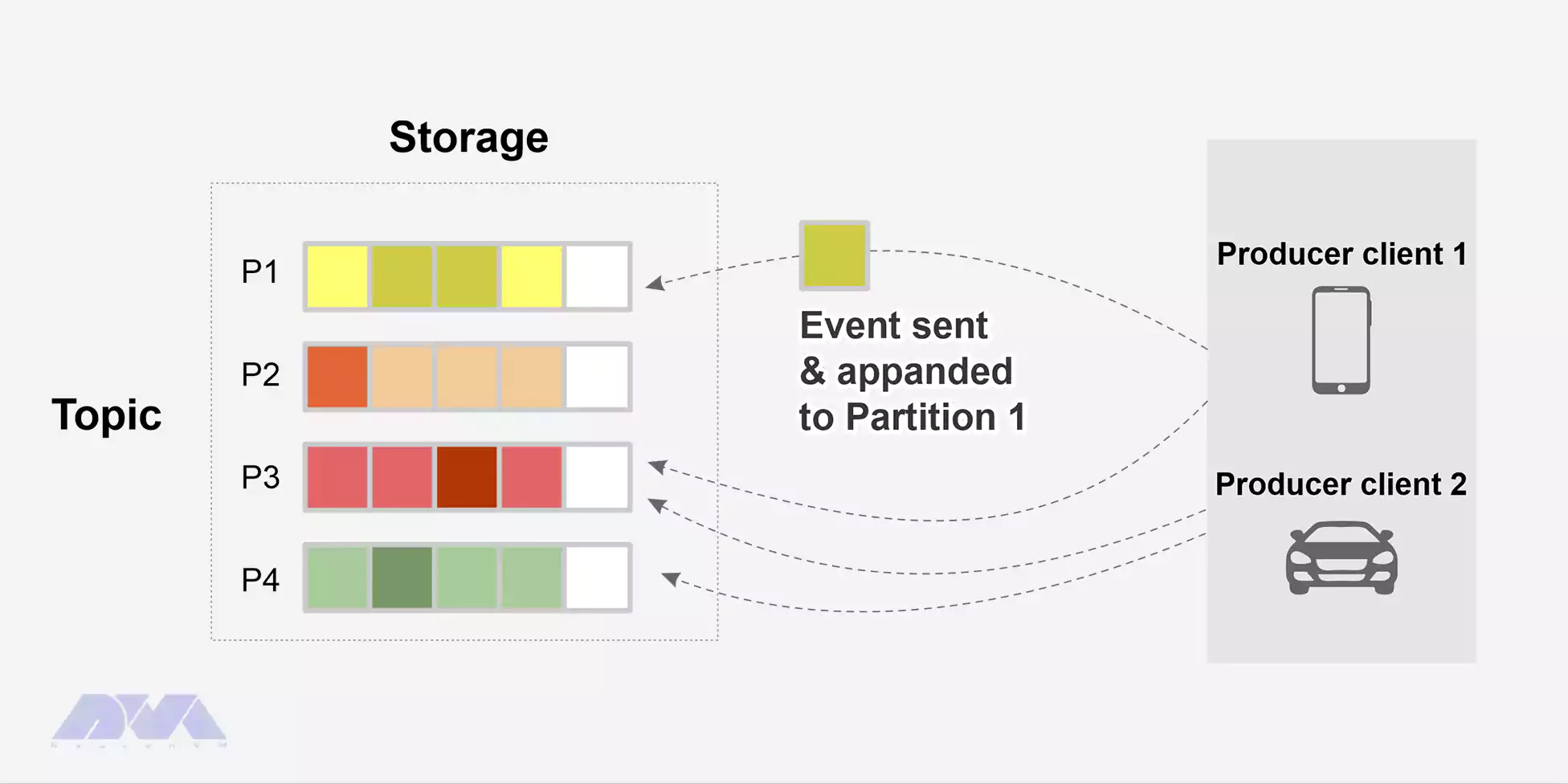
Kafka has a distributed architecture with multiple brokers working together in a cluster. Producers publish data to topics, and consumers subscribe to those topics to receive and process the data.
Topics are partitioned, and each partition is replicated across multiple brokers to ensure fault tolerance and high availability.
To better understand the flow of events, we can refer to the functioning of the human nervous system, which is a digital equivalent for this system.
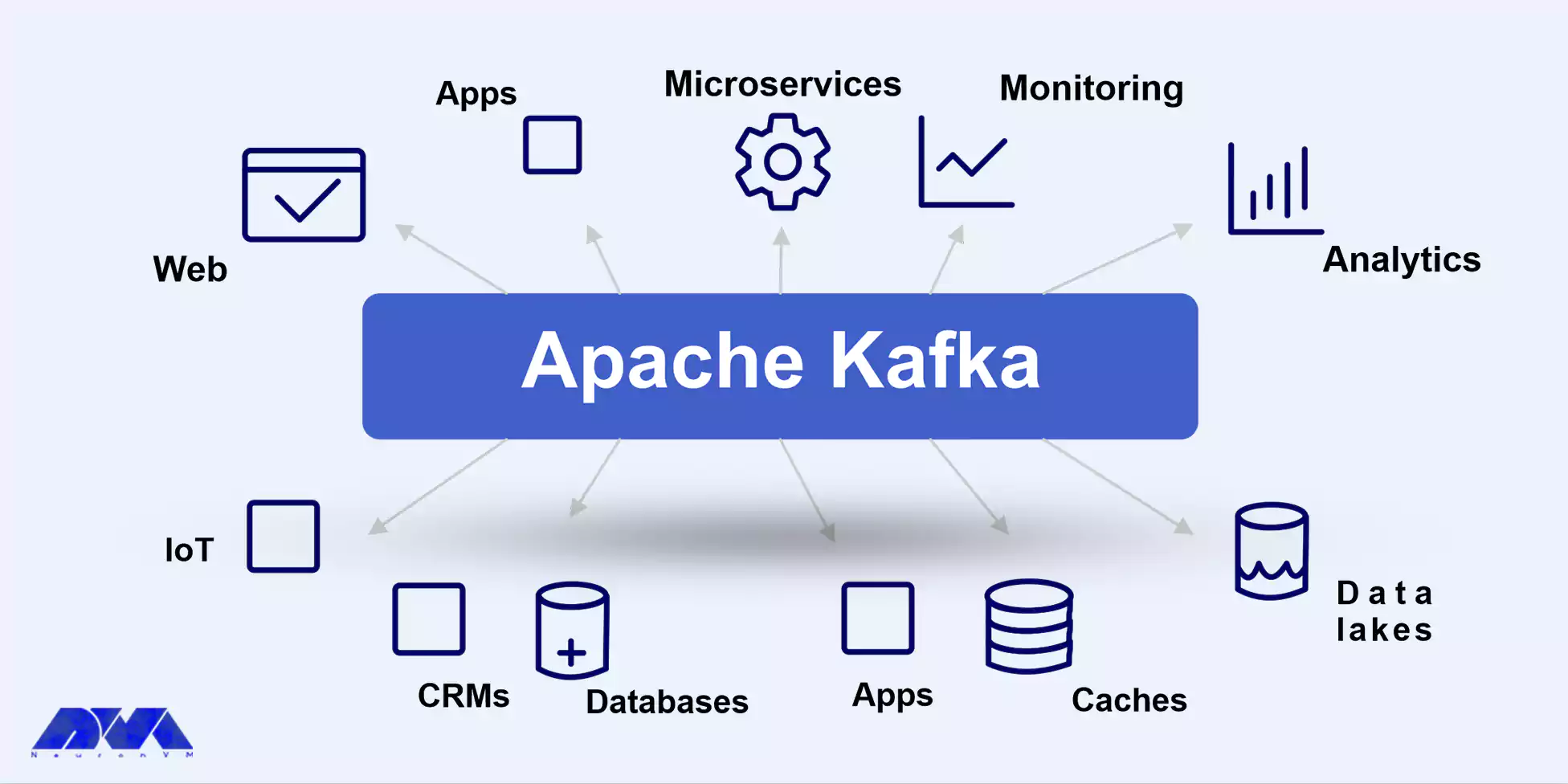
It is a digital platform for an always-on world where businesses are modernizing and automating. And their main user is actually software.
The function of the event stream is to record data in real-time from event sources such as databases, mobile phones, cloud services, software, etc. In the form of the event stream.
These event streams are stored persistently for later retrieval, real-time stream manipulation and processing, event stream routing, and more. In this way, the flow of events and the continuous interpretation of data are guaranteeing so that the right information is at the right time and place.
Here is an example of a ride-share system. You can see the following event:
– The event key: Ken
– Event value: a payment of 500$ to Peter
– Event Timestamp: “Jun. 27, 2022 at 2:00 p.m.”
If we want to point out the key concepts of Kafka, we should say that this platform is a distributed system of different servers and clients that interacts with events using the high-performance TCP network protocol. These components are designed to work together in harmony.
Below we explain some of these key concepts:
These components collectively form the Kafka ecosystem.
Kafka is a system of clients and servers. This platform can be deployed on bare-metal hardware, virtual machines, and containers.
Clients: Clients help you write the created programs and microservices. These programs read, write, and process streams of events in parallel, at scale, and in a fault-safe manner. Kafka also comes with dozens of such clients.
Kafka clients are available for Java and Scala, including the high-level Kafka streams library, C/C, Go++, and many other programming languages, as well as APIs.
Servers: Kafka is structured in such a way that it runs as a cluster of one or more servers. It is like it runs as a cluster of one or more servers and is able to cover different data centers or cloud regions. Kafka servers form a storage layer called a worker.
Also, other servers run Kafka content. This is done so that data is continuously imported and exported as event streams and Kafka is integrated into your existing systems, such as relational databases and other Kafka clusters. It is Fault-tolerant. In other words, If one of your servers fails, other servers will take over and ensure continuous operation.
Here are some use cases of Apache Kafka:
– Log Aggregation: Kafka is used to collect and aggregate logs from various sources.
– Real-time Data Processing: It’s used to process and analyze data streams in real time.
– Event Sourcing: Kafka can be used to implement event sourcing, a pattern for capturing changes to an application’s state.
– IoT (Internet of Things): Kafka can handle the high-throughput data generated by IoT devices.
– Metrics and Monitoring: It’s used for collecting and processing application and system metrics.
Kafka APIs (Application Programming Interfaces) are a set of interfaces and protocols that allow applications to interact with Apache Kafka, an open-source distributed event streaming platform. These APIs enable producers to publish data, consumers to subscribe and retrieve data, and other operations for managing and monitoring Kafka clusters.
Here is the list of core APIs for Kafka:
Apache Kafka is a popular distributed streaming platform that is used for building real-time data pipelines and streaming applications.
It can encounter common issues, so here we will show some of them along with potential solutions:
1- One or more Kafka brokers become unresponsive or fail.
Solution:
2- Some topic partitions are unavailable, leading to data loss or imbalance.
Solution:
3- Kafka brokers run out of disk space.
Solution:
4- Kafka relies on Apache ZooKeeper, which can be a single point of failure and complexity.
Solution:
Kafka has become a fundamental component of modern data architectures and is widely adopted in industries where real-time data processing and analytics are essential. However, users should be prepared to invest time in learning and setting up this great platform. So this article was focused on giving useful information and creating informative content for users. In our infographic post, we have comprehensively compared Confluent Kafka vs Apache Kafka, which we recommend you to read.
 Tags
Tags






If you want to know how to configure a DNS server on admin RDP, the following article will be a help...



 Tags
Tags

SteamCMD is a command-line tool developed by Valve. This tool is used to download, update, and manag...
Tags








